View the complete source code and Supabase schema on GitHub ↗
In the midst of inflation, supply chain disruptions, and current economic uncertainty, controlling cash flow is no longer just a good habit—it is a survival skill.
But let's be honest: manually logging every digital payment receipt or grocery store bill into a spreadsheet is exhausting. The friction of data entry is the primary reason personal budgeting fails.
I built Pocket CFO: an automated personal finance command center. I simply snap a photo of a receipt or forward a payment screenshot to a Telegram Bot. Behind the scenes, AI extracts the merchant name, unit prices, and categories directly into a Supabase database. A React dashboard then renders the analytics. Zero manual data entry.
Fig 0. The Magic: Forwarding a receipt in Telegram and watching the React dashboard render the itemized data instantly.
This is a deep dive into the engineering decisions, infrastructure pivots, and UI/UX empathy required to build a resilient, zero-cost, end-to-end full-stack pipeline.
The Problem: Data Silos, Friction, and Micro-Inflation
The journey to building Pocket CFO didn't start with a desire to play with AI; it started with a genuine frustration over personal financial tracking.
Over the years, I tried two distinct approaches to manage my cash flow, and both failed:
- Mainstream Apps (e.g., Money Lover): These apps are great for surface-level tracking, but the data is completely siloed. I couldn't run custom SQL queries to analyze my spending habits or extract my own data for deeper analytics.
- Building a Custom CRUD App: I built my own expense tracker, but I quickly discovered "Friction Fatigue." The discipline of manually typing in every transaction only lasted about a month before it felt like a chore.
The Breaking Point: Item-Level Analytics As someone who manages weekly grocery shopping for meal prepping, categorizing an entire receipt simply as "Groceries" wasn't enough. I wanted item-level granularity. I wanted to know the exact price per kilogram of chicken breast at Supermarket A versus Supermarket B. I wanted to track the historical price of avocados over a six-month period to monitor local micro-inflation.
Furthermore, I needed a real-time "Safe to Spend" metric—a clear liquidity indicator that tells me if buying a coffee today aligns with my long-term savings goals.
I needed a system that offered the deep, item-level analytics of a custom database, but with absolute zero data entry friction. That is when I realized I had to build an automated data ingestion pipeline.
1. The Macro Architecture & Tech Stack
To achieve frictionless input and rich data visualization without burning through server costs, I designed a completely decoupled architecture.
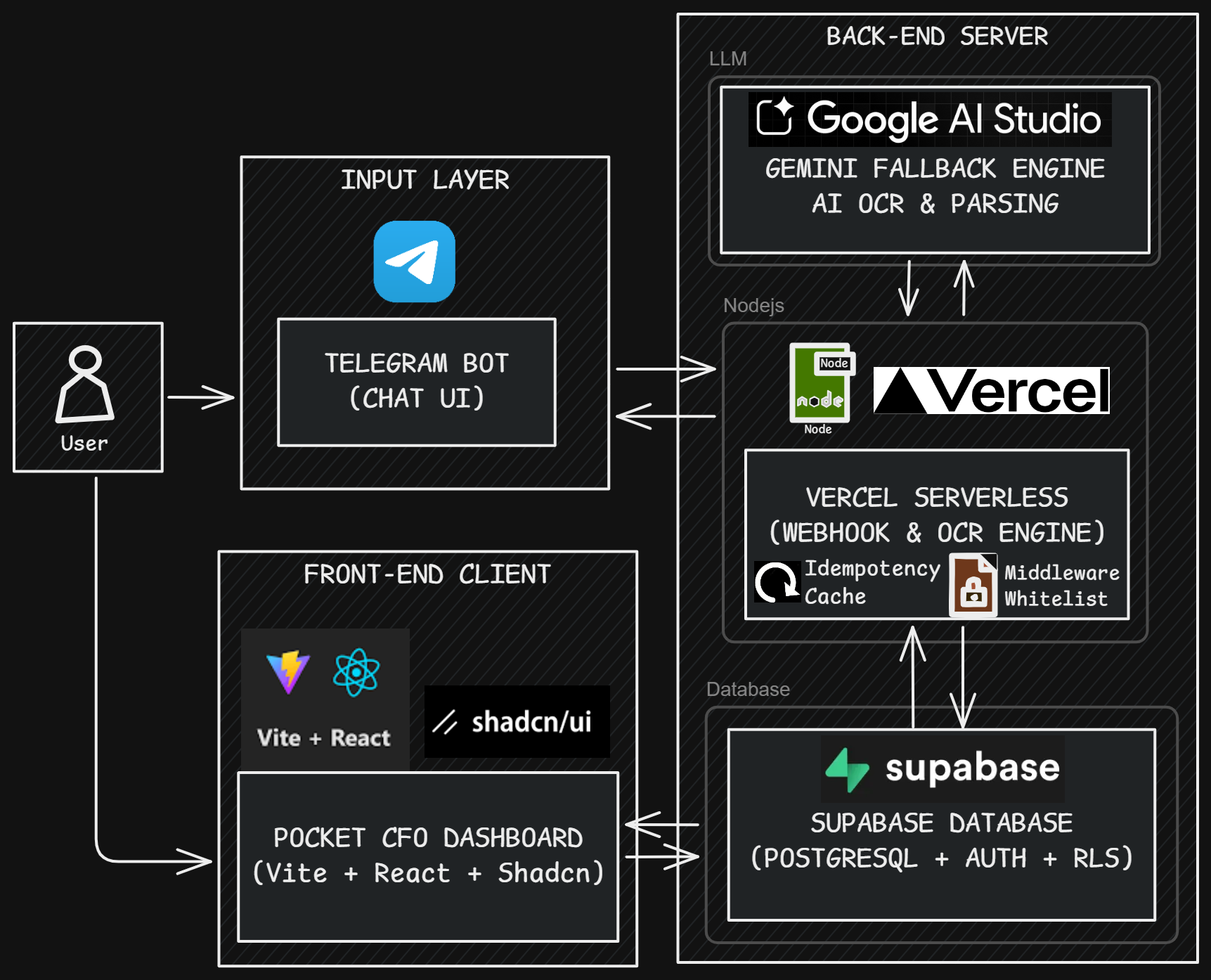
Fig 1. The Decoupled Pipeline: From Telegram webhooks to Supabase RLS and React rendering.
- Input Layer (Telegram Bot): The perfect frictionless UI. No new apps to install; it lives where I already chat.
- Compute Layer (Vercel Serverless): Acts as the webhook interceptor. Chosen for its zero-maintenance scaling.
- AI Brain (Google Gemini): Responsible for parsing unstructured natural language and OCR into strict JSON formats.
- Data Layer (Supabase/PostgreSQL): Handles storage, Row Level Security (RLS), and backend heavy computations.
- Presentation Layer (Vite + React + Tailwind): A lightning-fast, responsive dashboard using Shadcn UI.
2. Infrastructure: The Serverless Webhook & The Retry Loop
Engineering is often about finding loopholes—both technical and administrative.
When building the Telegram bot backend, my initial plan was to host a stateful Node.js (Telegraf) process on Render to keep the bot constantly listening. The reality? I hit an administrative wall. Render required a Stripe credit card verification even for the free tier, and their system repeatedly rejected my local bank cards.
I had to pivot to keep the infrastructure zero-cost. I shifted to a stateless architecture using Vercel Serverless Functions.
However, moving to serverless triggered a massive boss fight: The Infinite Retry Loop. Telegram's webhook mechanics are rigid; if your server does not respond with an HTTP 200 within 5 seconds, Telegram assumes the server is dead and continuously resends the exact same payload. Because AI processing routinely takes 6-10 seconds, my database was instantly flooded with duplicate transactions.
Responding with an HTTP 500 is lethal in a serverless environment (it just encourages more retries), so I engineered a custom Edge Idempotency Layer to gracefully break the loop during warm boots.
// Vercel Serverless / Edge Idempotency Layer
const processedUpdates = new Set();
module.exports = async (req, res) => {
const updateId = req.body.update_id;
// Intercept Telegram retries using global state during warm boots
if (updateId) {
if (processedUpdates.has(updateId)) {
console.log(`[Idempotency] Dropped duplicate ID: ${updateId}`);
return res.status(200).send('OK');
}
processedUpdates.add(updateId);
// Memory Management: Prevent Set from bloating RAM
if (processedUpdates.size > 100) {
processedUpdates.delete(processedUpdates.values().next().value);
}
}
// Acknowledge immediately to stop Telegram, process AI asynchronously
await bot.handleUpdate(req.body);
res.status(200).send('OK');
};
3. The AI Engine: Battling Rate Limits & Building Fallbacks
Selecting an AI model for production is a constant compromise between accuracy, speed, and cost.
Initially, I used gemini-2.5-flash for the OCR feature. The results were great, but parsing long, monthly grocery receipts requires heavy context windows. I quickly hit the token limit constraints on the free tier.
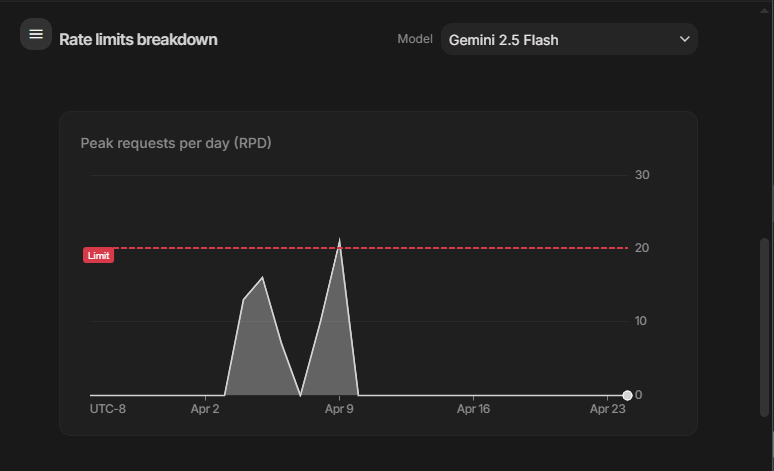
Fig 2. The Reality of Zero-Cost Infrastructure: Hitting the Free Tier limits on Google AI Studio.
The Local LLM Experiment: To bypass limits, I attempted to host local models (Ollama with MiniCPM-V). The result? Smaller models suffered from severe hallucinations and completely broke my JSON formatting requirements. I scaled up to an 8B parameter local model. The accuracy was perfect, but my laptop CPU throttled, and processing a single receipt took agonizing minutes.
The Solution: I abandoned local hosting and engineered a Cloud Fallback Array. The system now relies on an intelligent queue of Google's lightweight preview models. If one endpoint throws a 429 Too Many Requests error, the exponential backoff mechanism automatically degrades to the backup model.
// AI Orchestration / The Fallback Array
const GEMINI_MODELS = [
'gemini-3.1-flash-lite-preview', // Primary: Fast, lightweight
'gemini-3.0-flash-preview', // Fallback 1: Balanced
'gemini-2.5-flash', // Fallback 2: Legacy reliable
];
async function callGemini(prompt, imageBuffer) {
for (const modelName of GEMINI_MODELS) {
try {
const model = genAI.getGenerativeModel({ model: modelName });
const result = await model.generateContent({
contents: buildPayload(prompt, imageBuffer),
// System Prompt ensures strict JSON categorization
generationConfig: { responseMimeType: 'application/json' },
});
return JSON.parse(result.response.text());
} catch (error) {
console.warn(`[AI Engine] ${modelName} failed. Falling back...`);
if (modelName === GEMINI_MODELS[GEMINI_MODELS.length - 1]) throw error;
}
}
}
4. Zero-Trust Security & Database Schema
Threat modeling is crucial. The most common question I get is: "What if someone finds your Telegram bot and sends random receipts? Will it ruin your database?"
The answer lies in a Zero-Trust Architecture. Because the Vercel endpoint is publicly accessible on the internet, I secured the pipeline at two distinct layers.
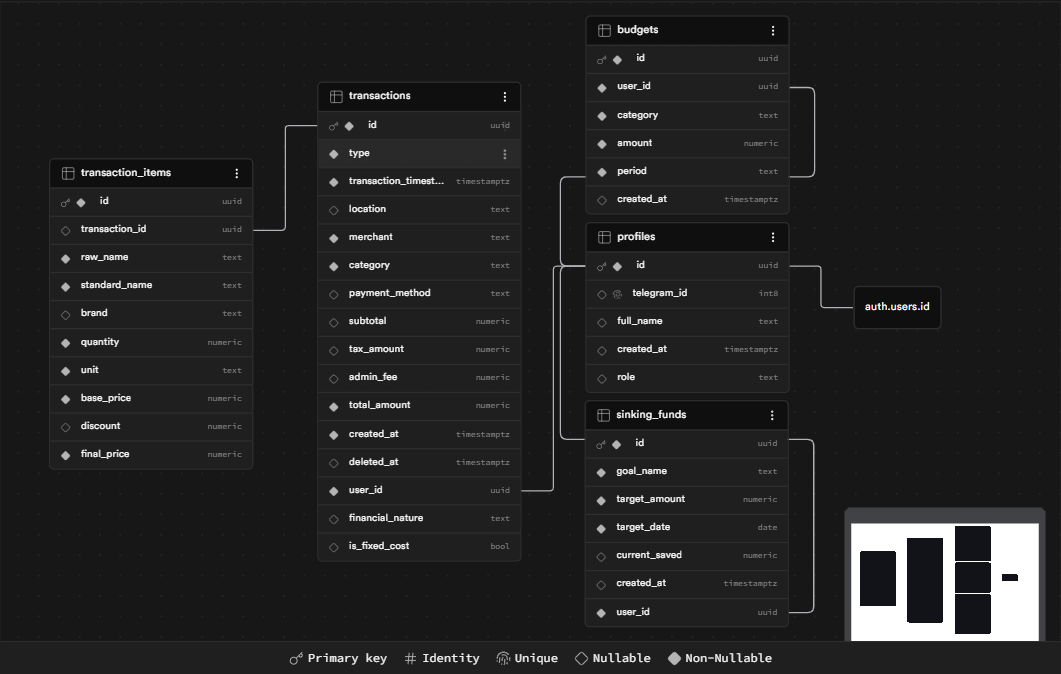
Fig 3. The Relational Backbone: Transactions, Items, and Budgets linked strictly by user UUIDs.
Layer 1: The Middleware Whitelist
The bot is not open to the public. Before a request even touches the AI engine, a Telegraf middleware intercepts it and queries the Supabase profiles table using ctx.from.id. If your Telegram ID is not whitelisted, the request is instantly dropped.
// Telegram Middleware / ID Validation
bot.use(async (ctx, next) => {
const telegramId = ctx.from.id;
const { data: user, error } = await supabase
.from('profiles')
.select('id')
.eq('telegram_id', telegramId)
.single();
if (error || !user) {
return ctx.reply('🚫 Unauthorized access. Your ID is not whitelisted.');
}
ctx.session.userId = user.id; // Inject UUID into session for downstream inserts
return next();
});
Layer 2: Supabase Row Level Security (RLS)
On the web dashboard side, data is protected by Supabase's strict RLS. Even if the Vercel API endpoint was compromised, the database policies ensure that an authenticated user can only execute SELECT, INSERT, or DELETE on records matching their own UUID.
-- PostgreSQL / Row Level Security
ALTER TABLE "public"."transactions" ENABLE ROW LEVEL SECURITY;
CREATE POLICY "Users manage their own data"
ON "public"."transactions"
FOR ALL TO "authenticated"
USING (("auth"."uid"() = "user_id"));
5. Engineering Empathy: Managing Data Density on Mobile
Having a background in both frontend development and backend architecture, building the UI wasn't about learning a new framework—it was an exercise in extreme data density management.
Raw JSON data securely resting in a database is useless if the visualization causes cognitive overload. I built the Pocket CFO Dashboard as a responsive Single Page Application (SPA) using Vite, React, and Shadcn UI.
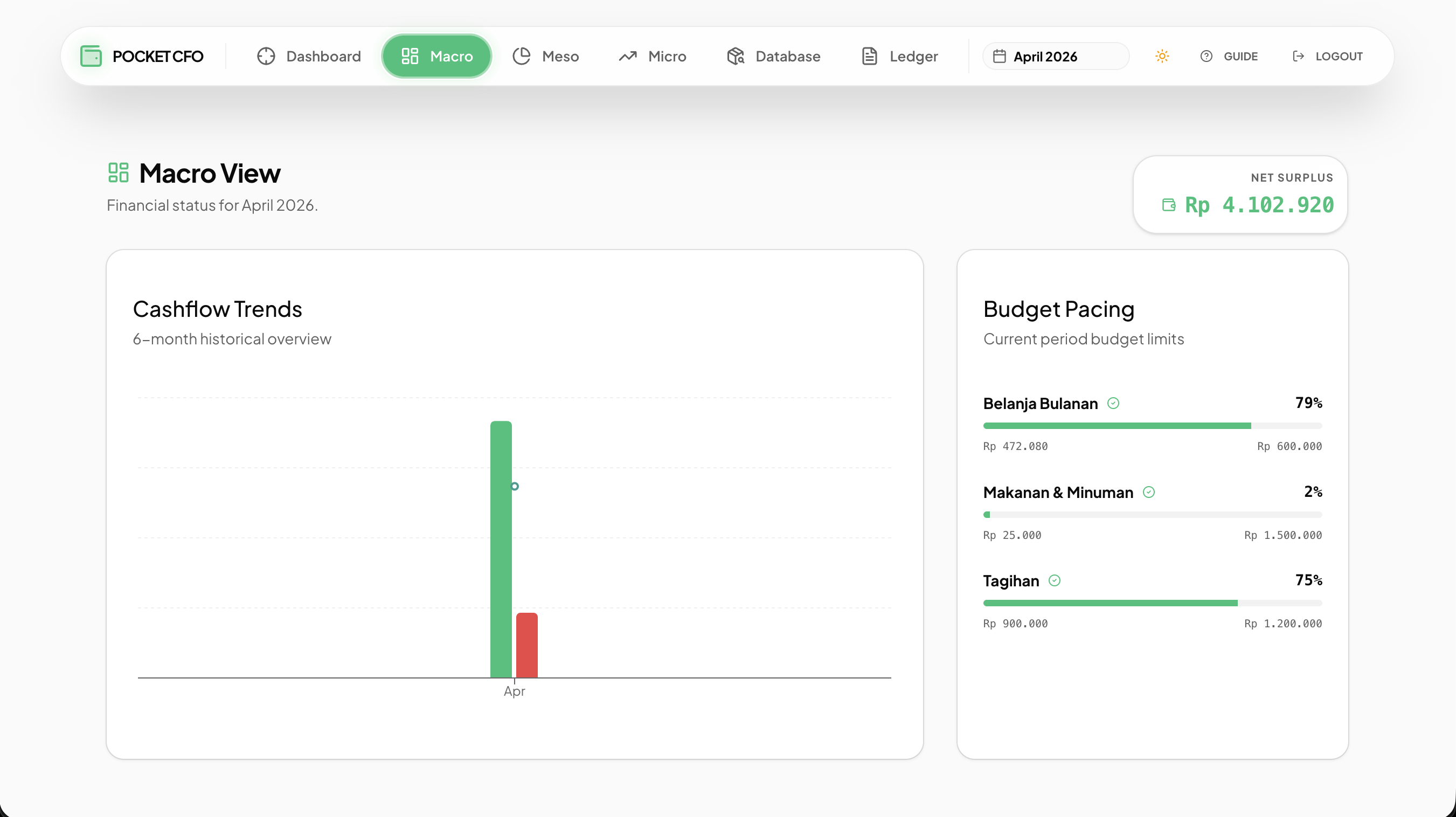
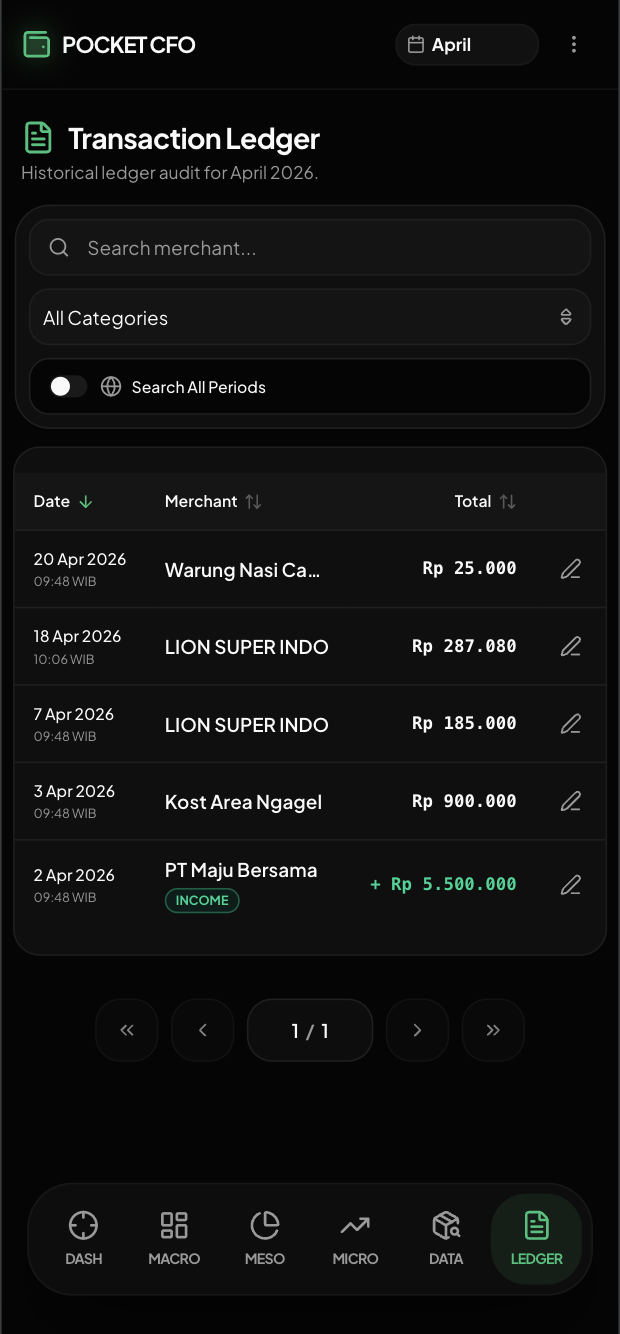
Fig 4. The Presentation Layer: Shadcn UI Recharts (top) and Dark Mode responsive tables (bottom).
The UX Dilemma: When you have rich, item-level data (Item Name, Category, Price, Date, Merchant, Tags), the full-stack instinct is often to just render a massive data grid. However, mobile screens have zero tolerance for cluttered tables and horizontal scrolling. Dense financial data feels suffocating on a 6-inch display.
Technical implementation must be balanced with product empathy. I made aggressive responsive adjustments using Tailwind CSS to prioritize mobile readability:
| Engineering Implementation | UX Purpose |
|---|---|
className="hidden md:table-cell" | Prevents horizontal scrolling on mobile by dynamically hiding secondary columns like 'Category'. |
Header Navigation (Kebab Menu) | Condenses secondary global utilities (Theme toggle, Guide, Logout) into a single dropdown on mobile screens, keeping the header clean and maximizing vertical real estate for the dashboard. |
Direct Supabase Client CRUD | The frontend bypasses intermediate APIs to fetch and mutate transaction data natively for instantaneous UI updates. |
Final Thoughts
This project was my way of using engineering to survive an unpredictable economy. Building Pocket CFO from end-to-end forced me to traverse the entire stack—from the unyielding timeouts of serverless architecture to the nuances of mobile data visualization.
Hopefully, this system architecture inspires other developers to build tools that solve their own everyday bottlenecks.